Tìm hiểu về công nghệ chuyển Sound/Audio sang văn bản sử dụng Deep Learning
Bevoice / February 1, 2024
Bên cạnh Images, Text thì Sound cũng là một dạng dữ liệu mà chúng ta thường gặp trong đời sống hàng ngày. Trong chuỗi 5 bài tiếp theo, chúng ta sẽ tìm hiểu chi tiết về bài toán Audio Classification và Speech Recognition (Speech to Text).
- Bài 1: Giới thiệu chung về bài toán Audio Clasifidation
- Bài 2: Mel Spectrograms
- Bài 3: Feature Optimization and Augmentation
- Bài 4: Xây dựng Audio Classification model bằng PyTorch
- Bài 5: Tìm hiểu bài toán Speech Recognition (Speech to Text)
Nội dung của bài đầu tiên bao gồm một số lý thuyết chung về Audio, các ứng dụng liên quan đến Sound. Chúng ta cũng tìm hiểu về Spectrogram và một số kỹ thuật, kiến trúc mô hình để làm việc với Sound.
1. Kiến thức chung về Sound Signal
Từ hồi học phổ thông chúng ta đã biết, Sound là một dạng tín hiệu được sinh ra từ sự thay đổi áp suất không khí, bắt nguồn từ một dao động cơ học nào đó. Cường độ của sự thay đổi áp suất này có thể đo được, và nó chính là biên độ (Applitude) của Sound Signal.
Sound Signal thường lặp đi lặp lại theo một chu kỳ T, đồ thị của nó có dạng sóng.
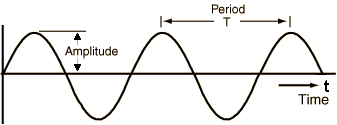
Giá trị nghịch đảo của chu kỳ T, ký hiệu là f, gọi là tần số của Sound Signal. Nó thể hiện mức độ dao động của Signal trong thời gian 1s (bằng số đỉnh của Signal trong 1s). Đơn vị của f là Hertz.
Trong thực tế, đồ thị của Sound Signal thường không đơn giản dạng Sin như vậy, mà phức tạp hơn rất nhiều. Tuy nhiên, chúng vẫn có dạng sóng và có chu kỳ. Ví dụ, đồ thị của một dụng cụ âm nhạc như dưới đây:

Nhìều Sound Signal có thể được tổng hợp thành một Sound Signal duy nhất.
Về mặt cảm thụ sinh học, mỗi Sound Signal có một đặc trưng riêng, gọi là âm sắc (timbre). Tai người có thể phân biệt được các Sound khác nhau dựa vào âm sắc của các Sound đó.
2. Số hóa (Digitize) Sound Signal
Nguyên bản, Sound Signal là một dạng tín hiệu tương tự (Analog Signal) liên tục theo thời gian. Tuy nhiên, để thuận lợi trong việc lưu trữ, xử lý và truyền tải, Sound Signal được chuyển sang dạng Số (Digital Signal). Việc chuyển đổi này phải đảm bảo không làm mất mát quá nhiều thông tin so với tín hiệu gốc, và từ tín hiệu đã chuyển đổi có thể dễ dàng khôi khục lại gần như nguyên vẹn tín hiệu ban đầu. Số hóa Sound Signal được thực hiện bằng cách lấy giá trị biên độ của nó tại các vị trí cách đều nhau trong mỗi chu kỳ.
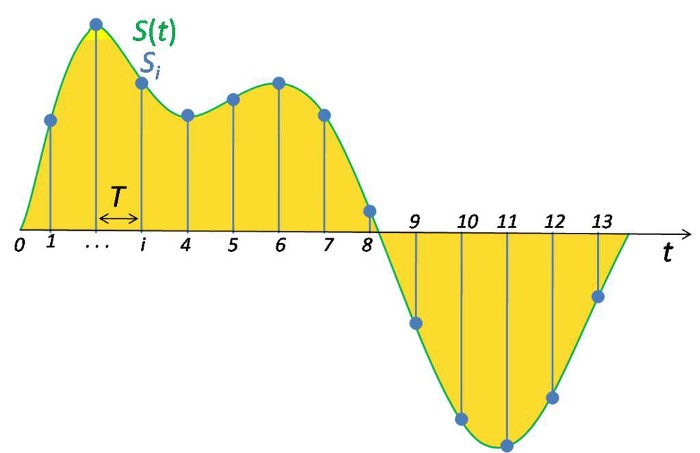
Mỗi vị trí như vậy được gọi là một mẫu (Sample). Ta có khái niệm Tần số lấy mẫu (Sample Rate) là số lượng mẫu trong 1s.
Một câu hỏi đặt ra là giá trị của Sample Rate là bao nhiêu là hợp lý. Hai nhà khoa học Nyquist và Shannon đã đồng thời, độc lập đưa ra một định lý, gọi là Định lý lấy mẫu Nyquist–Shannon, về việc xác đinh giá trị của Sample Rate. Định lý phát biểu như sau:
Một hàm số tín hiệu x(t) không chứa bất kỳ thành phần tần số nào lớn hơn hoặc bằng một giá trị fm có thể biểu diễn chính xác bằng tập các giá trị của nó với chu kỳ lấy mẫu T = 1/(2fm).
Từ định lý này có thể dễ dàng suy ra, Tần số lấy mẫu phải thoả mãn điều kiện
Định lý Nyquist–Shannon được áp dụng cho tín hiệu nói chung chứ không phải chỉ riêng tín hiệu âm thanh.
Đến đây, chúng ta cần phân biệt được 2 khái niệm Audio và Sound. Sound có nguồn gốc là các dao động cơ học lan truyền trong các môi trường đàn hồi (rắn, lỏng, khí), còn Audio được sinh ra từ các thiết bị điện tử thông qua quá trình lấy mẫu, ghi âm, …
3. Chuẩn bị dữ liệu Audio cho Deep Learning model
Hãy nhớ lại khoảng 10 năm trước, khi mà các kỹ thuật Deep Learning còn chưa phát triển, chúng ta phải sử dụng các phương pháp thống kê, xử lý truyền thống để có thể trích xuất được các đặc trưng làm đầu vào cho các thuật toán Machine Learning. Cụ thể, đối với lĩnh vực Computer Vision, chúng ta sử dụng các kỹ thuật xử lý ảnh như phát hiện biên, ngưỡng nhị phân, … Đối với lĩnh vực NLP, chúng ta sử dụng phương pháp N-gram, Term Frequency, …
Dữ liệu Audio cũng không ngoại lệ, chúng ta phải thực hiện rất nhiều công việc tay chân, sữ dụng các phương pháp phân tích ngữ âm, âm vị, … để có thể tạo được các vectors đặc trưng của chúng.
Ngày nay, với sự trợ giúp của Deep Learning, việc trích xuất đặc trưng để chuẩn bị dữ liệu cho các mô hình học máy trở nên đơn giản hơn rất nhiều. Riêng đối với dữ liệu Audio, chúng ta sẽ chuyển chúng sang dạng Image và sử dụng kiến trúc CNN kinh điển để xử lý chúng. Từ Audio chuyển sang Image, điều này nghe có vẻ rất kỳ lạ, nhưng thực tế đó lại là cách làm rất bình thường trong các bài toán xử lý dữ liệu Audio. Để hiểu rõ hơn về vấn đề này, trước tiên chúng ta cần tìm hiểu Spectrum và Spectrogram.
Hình dưới đây thể hiện Spectrum của một đoạn nhạc. Trục tung là giá trị biên độ, trục hoành là giá trị tần số của mỗi tín hiệu thành phần.
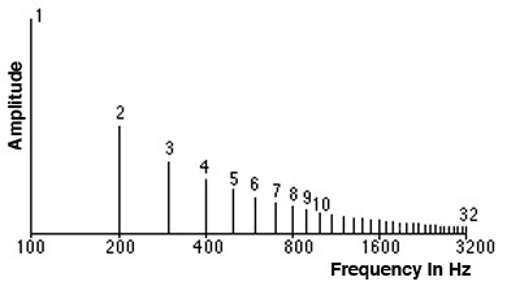
Tần số có giá trị nhỏ nhất được gọi là tần số Cơ bản. Các tần số khác là bội số của tần số cơ bản được gọi là Sóng hài (harmonics). Ví dụ, nếu tần số cơ bản là 200Hz, thì các sóng hài của nó là 400Hz, 600Hz, …
3.1 Spectrum
Như đã nói ở trên, một Sound Signal trong thực tế thường là sự tổng hợp của nhiều tín hiệu thành phần khác nhau. Ví dụ, tiếng nói của chúng ta bao gồm cả các tạp âm (Noise) xung quanh. Mỗi tín hiệu thành phần đó lại có tần số khác nhau, và do vậy, tổng hợp các tần số thành phần ta có tần số của Sound Signal.
Spectrum chính là tập hợp các tần số của các tín hiệu thành phần tạo nên Sound Signal của chúng ta.
3.2 Miền thời gian và miền Tần số
Mỗi Sound Signal đều có 2 miền giá trị: Thời gian và Tần số. Trong mỗi miền đó, Sound Signal được thể hiện theo cách khác nhau.
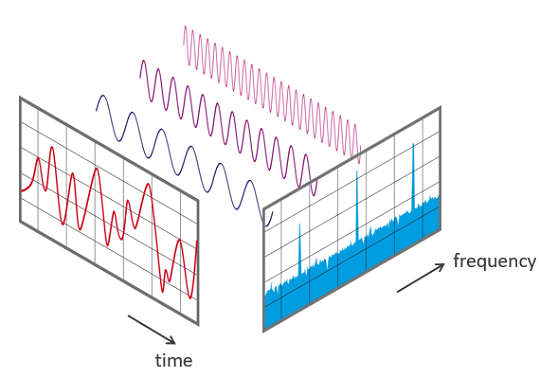
- Thể hiện trong miền thời gian Trong miền thời gian, Sound Signal mô tả sự thay đổi của biên độ theo thời gian. Biên độ nằm trên trục tung và thời gian nằm trên trục hoành (xem đồ thị bên trên).
- Thể hiện trong miền tần số Trong miền tần số, Sound Signal mô tả sự thay đổi của biên độ theo tần số. Biên độ nằm trên trục tung và tần số nằm trên trục hoành (xem đồ thị bên trên).
3.3 Spectrogram
Ở mục 3.2, ta đã nói đến mỗi liên hệ giữa biên độ với thời gian và biên độ với tần số. Hơn thế nữa, tần số và và thời gian cũng có mối liên hệ với nhau. Đồ thị thể hiện mối liên hệ này gọi là Spectrogram, trong đó, trục X thể hiện thời gian và trục Y thể hiện tần số. Nói một cách dễ hiểu thì Spectrogram thể hiện sự thay đổi của tần số theo thời gian. Không chỉ có vậy, độ lớn của biên độ cũng được Spectrogram thể hiện thông qua màu sắc. Màu sắc càng sáng thì thì biên độ càng lớn và ngược lại.
Trong 2 hình bên dưới, hình thứ nhất thể hiện Soung Signal trong miền thời gian. Tại t = 600000, biên độ có giá trị lớn nhất. Hình thứ 2 là Spectrogram của Sound Signal đó. Tương ứng với giá trị lớn nhất của biên độ là vùng màu sắc sáng nhất trên Spectrogram.
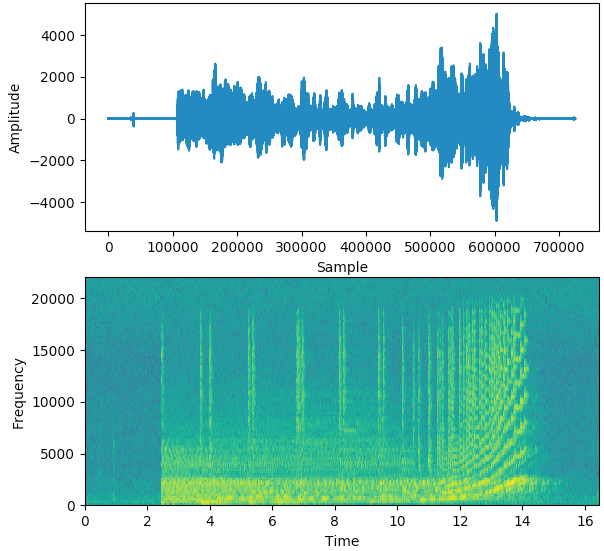
Có thể nói, Spectrogram là cách thể hiện tốt nhất của Sound Signal, dưới dạng một hình ảnh, bởi vì nó mang đầy đủ thông tin về thời gian, tần số và biên độ. Và do vậy, Spectrogram được sử dụng làm dữ liệu đầu vào cho các Deep Learning model, như một bức ảnh thông thường.
Spectrogram được sinh ra bằng cách áp dụng phép biến đổi Fourier lên một Signal để phân tách Signal đó thành các tần số thành phần. Có lẽ đa số chúng ta đã quên mất cách tính Fourier bằng tay như thế nào, mặc dù chúng ta đã được học ở bậc đại học. Rất may là có một số thư viên của Python sẽ giúp chúng ta thực hiện Fourier Transform một cách dễ dàng.
4. Audio Deep Learning models
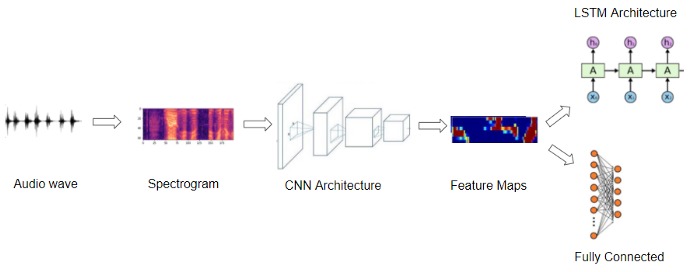
Hầu hết các Deep Learning models đều sử dụng Spectrograms để làm đặc trưng cho Audio. Luồng xử lý sẽ như sau:
- Chuyển đổi Raw Audio sang Spectrogram.
- Áp dụng một số kỹ thuật tăng cường dữ liệu. Các kỹ thuật này cũng có thể áp dụng cho Raw Audio. Bước này không bắt buộc.
- Xây dựng CNN model và huấn luyện nó.
- Output của CNN là các Feature Maps. Tùy vào bài toán cụ thể mà chúng ta sinh ra các dạng Output khác nhau.
- Audio Classification: Cho Feature Maps đi qua một bộ phân lớp (FC, SVM, …) để sinh ra nhãn cho Audio
- Speech to Text: Cho Feature Maps đi qua RNN để sinh ra Text tương ứng với Audio.
5. Một số bài toán mà Deep Learning có thể giải quyết đối với dữ liệu Audio
Audio luôn tồn tại xung quanh chúng ta: giọng người nó, tiếng kêu động vật, tiếng máy móc hoạt động, … Áp dụng Deep Learning, chúng ta có thể giải quyết được một số bài toán sau:
5.1 Audio Classification
Đây có lẽ là bài toán phổ biến nhất của Audio. Input là 1 đoạn Audio, Output là nhãn của nó.
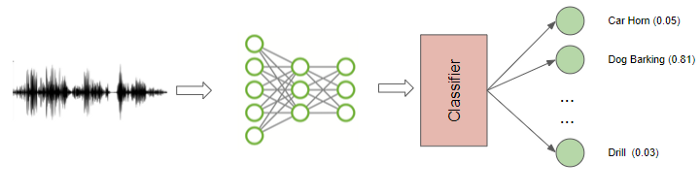
Một số ứng dụng thực tế của bài toán này:
- Phát hiện sự hư hỏng của máy móc thông qua tiếng kêu khi hoạt động bình thường và khi hư hỏng.
- Phát hiện trộm dựa vào phát hiện tiếng đập vỡ cữa kính
- Phát hiện bệnh thông qua tiếng ho, tiếng thở
- …
5.2 Audio Separation and Segmentation
Bài toán này liên quan đến viêc tách riêng các tín hiệu thành phần từ tín hiệu gốc ban đầu.
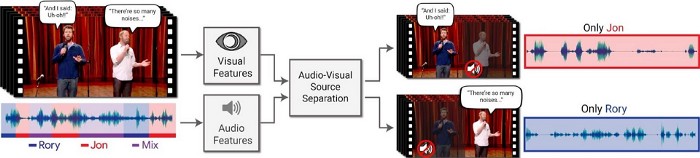
Một số ví dụ ứng dụng thực tế:
- Tách riêng giọng của mỗi người trong 1 cuộc họp.
- Tách riêng âm thanh của một loại nhạc cụ trong một buổi hòa nhạc.
- Tách giọng ca sĩ khỏi bài hát.
5.3 Music Generation and Music Transcription
Cũng giống như GAN hay Language Model, một số Deep Learning model có thể sinh ra các bản nhạc theo thể loại, loại nhạc cụ hay thậm chí là phong cách của một nhạc sĩ cụ thể. Đó gọi là Music Generation.
Ở chiều ngược lại, từ một bản nhạc dạng Audio, Deep Learning model có thể dịch ngược lại thành Text, kèm theo giai điệu, node nhạc, …
5.4 Voice Recognition
Thực chất, đây cũng là bài toán Audio Classification nhưng được áp dụng cho giọng nói của con người.
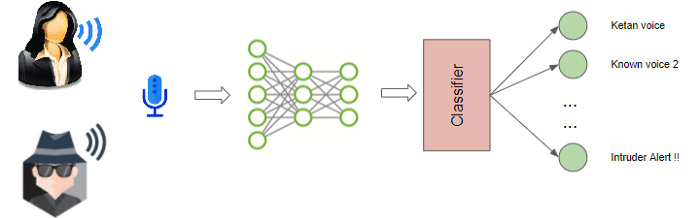
Một số ứng dụng thực tế của bài toán này:
- Phân biệt giọng nam và giọng nữ
- Nhận diện tên người thông qua giọng nói của họ
- Nhận diện cảm xúc thông qua giọng nói của họ
- …
5.5 Speech to Text and Text to Speech
Đối với giọng nói của con người, chúng ta có thể đi sâu hơn một chút. Đó là không chỉ nhận dạng người nói là ai mà còn có thể hiểu được người đó nói gì. Điều này được gọi là bài toán Speech to Text, tức chuyển Audio thành văn bản.
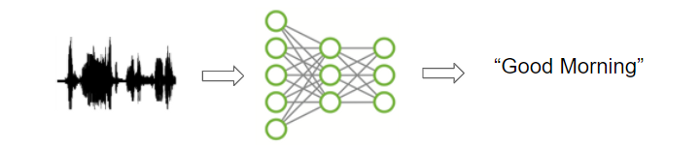
Theo hướng ngược lại, chúng ta có bài toán Text to Speech, hay Speech Synthesic, tức là chuyển đổi một văn bản thành dạng Audio.
Cả 2 bài toán này đều có rất nhiều ứng dụng hữu ích trong cuộc sống, ví dụ như trợ lý ảo thông mình Siri, Alexa, Cortana hay Google Home.
6. Kết luận
Bài đầu tiên trong chuỗi các bài viết về Audio Deep Learning này, chúng ta đã tìm hiểu ở mức khái quát lý thuyết về Sound Signal, các số hóa Sound Signal, cách tạo dữ liệu cho Deep Learning model sử dụng Spectrogram. Cuối cùng, chúng ta cũng điểm qua một số bài toán cụ thể mà Deep Learning có thể giải quyết đối với dữ liệu Audio.
Ở bài tiếp theo, mình sẽ cùng các bạn tìm hiểu chi tiết về Mel Spectrogram, một dạng biến đổi khác từ Spectrogram mà có thể giúp cho các Deep Learning model học tốt hơn. Mời các bạn đón đọc.
(Nguồn tiensu blog)
7. Tham khảo
[1] Ketan Doshi, “Audio Deep Learning Made Simple (Part 1): State-of-the-Art Techniques”, Available online: https://towardsdatascience.com/audio-deep-learning-made-simple-part-1-state-of-the-art-techniques-da1d3dff2504 (Accessed on 20 May 2021).
[2] Wikipedia, “Định lý lấy mẫu Nyquist–Shannon”, Available online: https://vi.wikipedia.org/wiki/%C4%90%E1%BB%8Bnh_l%C3%BD_l%E1%BA%A5y_m%E1%BA%ABu_Nyquist%E2%80%93Shannon (Accessed on 20 May 2021).
[3] Wikipedia, “Fourier transform”, Available online: https://en.wikipedia.org/wiki/Fourier_transform (Accessed on 20 May 2021).
[4] Wikipedia, “Spectrogram”, Available online: https://en.wikipedia.org/wiki/Spectrogram (Accessed on 20 May 2021).